дёҪжұҹжІіеҘ—еӯҰйҷўз»“еҗҲжҷәеӯҗиҠҜе…ғгҖҒжҳҮи…ҫAIгҖҒдёҪжұҹеёӮеӨ§ж•°жҚ®й’»з ”йҷўйҖҡиҝҮAgentй©ұеҠЁзҡ„дёҖдҪ“еҢ–жөҒж°ҙзәҝ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе®һзҺ°жЁЎеһӢиҝҒеҫҷзҷҫеҖҚж•ҲиғҪжҸҗеҚҮгҖҒжңәиғҪзІҫеҮҶдјҳеҢ–�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдёәеӣҪдә§з®—еҠӣзҡ„еӨҡиЎҢдёҡ规�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣеҶ’иҒӘйҡҶеҮ№ж¶Ңж—’и–„�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
еҪ“еүҚеӣҪдә§з®—еҠӣжӯЈиҝӣе…Ҙ规�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣж¶һдәҹй”Ҙ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢйқўеҜ№еӨҡиЎҢдёҡгҖҒеӨҡе·ҘдҪңзҡ„еҲ©з”ЁеңәжҷҜ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдёҖдёӘе…ій”®жҢ‘жҲҳжҳҜпјҡ
е…ЁзҗғеүҚжІҝжЁЎеһӢиғҪеҗҰеңЁеӣҪдә§AIиҠҜзүҮдёҠе®һзҺ°жҖҘеү§й…ҚзҪ®гҖҒй«ҳж•ҲиҝҗиЎҢ�пјҹпјҹ�пјҹ�пјҹпјҹ�пјҹ�пјҹ�пјҹ
еңЁеӣҪдә§з®—еҠӣдёҠ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢжЁЎеһӢиҝҒеҫҷйҖҡеёёеҝ…иҰҒеҮҢй©ҫдёӨи·Ҝе…іпјҡ
1пјүи®©жЁЎеһӢжҖҘеү§и·‘иө·жқҘпјҡ兼容硬件зҺҜеўғгҖҒPytorchжЁЎеһӢгҖҒеӣҪдә§иҠҜзүҮе·Іжңүз®—еӯҗзӯү�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣ
2пјүи®©жЁЎеһӢи·‘еҫ—жӣҙеҝ«пјҡе®ҡдҪҚжҺЁзҗҶй“ҫи·Ҝдёӯзҡ„瓶йўҲ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢ并иҝӣиЎҢзі»з»ҹжҖ§дјҳеҢ–гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
дј з»ҹжөҒзЁӢеҫҖеҫҖдҫқиө–дәәдёәз»ҸйӘҢдёҺеҸҚеӨҚиҜ•й”ҷ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢйҡҫд»Ҙж”ҜжҢҒеӨҡжЁЎеһӢзүҲжң¬гҖҒжҢҒз»ӯиҝӯд»Јзҡ„дәӨд»ҳиҠӮжӢҚгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮдёәжӯӨ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢжҲ‘们е°ҶвҖң规�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣйҖқ + з«ҜеҲ°з«ҜдјҳеҢ–вҖқиҙҜйҖҡдёәдёҖжқЎеҸҜеӨҚзҺ°гҖҒеҸҜйӘҢиҜҒзҡ„дәӨд»ҳй“ҫи·Ҝ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢжҠҠиҝҒеҫҷд»Һз»ҸйӘҢй©ұеҠЁзҡ„иҜ•й”ҷиҝҮзЁӢ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҪ¬дёәеҸҜеӨҚйҖ зҡ„е·ҘзЁӢжөҒзЁӢгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮзӣ®еүҚе·ҘдҪңжІүзӮ№йқўеҗ‘жҳҮи…ҫе№іеҸ°еҸ‘еұ•�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢеҗҢж—¶�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдё»йўҳжөҒзЁӢд№ҹе·ІеңЁе…¶д»–еӣҪдә§иҠҜзүҮе№іеҸ°дёҠе®һзҺ°еҲқжӯҘеҸҜиЎҢжҖ§йӘҢиҜҒгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ

д»ҺвҖңдёҖж¬ЎиғҪи·‘вҖқеҲ°вҖңжҢҒд№…еҸҜдәӨд»ҳгҖҒеҸҜжҸҗйҖҹвҖқ
01
з®Җд»Ӣпјҡ
д»ҺвҖңйҖӮй…Қйқ з»ҸйӘҢвҖқеҲ°вҖңдәӨд»ҳйқ зі»з»ҹвҖқ
дј з»ҹи·Ёе№іеҸ°иҝҒеҫҷеҫҖеҫҖеҮәзҺ°дёӨзұ»е…ёеһӢз—ӣзӮ№пјҡ
? зҺҜеўғзўҺзүҮеҢ–пјҡжҜҸдёӘжЁЎеһӢе®ҲжҠӨдёҖеҘ—й•ңеғҸ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдҫқиө–зҹӣзӣҫйў‘еҸ‘�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҝҒеҫҷе…Ёйқ жүӢе·ҘиҜ•й”ҷгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
? жңәиғҪдёҚжҲҗжҺ§пјҡеҚідҫҝвҖңиғҪи·‘вҖқ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢз«ҜеҲ°з«Ҝеҗһеҗҗеёёиў«йў„еӨ„зҪ®гҖҒи§Јз ҒеҫӘзҺҜгҖҒз®—еӯҗйҖүжӢ©зӯүжҲҗеҲҶйҡҗжҖ§з“¶йўҲжӢ–ж…ўгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
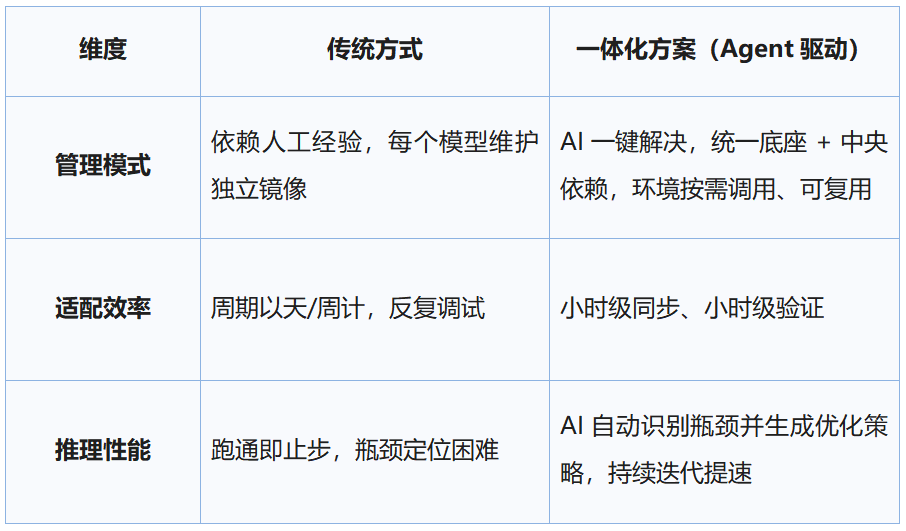
жҲ‘们用AgentеҢ–зҡ„дёҖдҪ“еҢ–规еҲ’жҠҠвҖңйҖӮй…ҚвҖ”дјҳеҢ–вҖқдёІжҲҗдёҖжқЎй“ҫи·ҜгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮдёӨдёӘ规еҲ’зҡ„еҜ№еҘҪжҜ”дёӢпјҡ
02
еӣҪдә§з®—еҠӣдёҠзҡ„规�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣпј°иӨӘйҖқ
жҲ‘们е°ҶеӨҚжқӮзҡ„硬件йҖӮй…Қз»ҸйӘҢеӣәеҢ–дёәеҸҜжү§иЎҢзҡ„жҷәиғҪдҪ“Skillе·ҘдҪңжөҒ�пјҹпјҹ�пјҹ�пјҹпјҹ�пјҹ�пјҹ�пјҹжӨӢг„—в…ІзҜ Killе·ҘдҪңжөҒжҢҮзҡ„жҳҜи®©AIеӯҰдјҡжү§иЎҢжҹҗйЎ№е…·дҪ“е·ҘдҪңзҡ„дё“й—ЁиғҪеҠӣжҲ–вҖңжҠҖжңҜжҢҮеҚ—вҖқпјүгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮиҝҷеҘ—йқўеҗ‘AIжҷәиғҪдҪ“зҡ„вҖңе·ҘзЁӢжҢҮеҚ— + е·Ҙе…·йӣҶвҖқ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдҪҝжҷәиғҪдҪ“еҸҜиғҪиҮӘеҠЁйүҙеҲ« NPU й©ұеҠЁе№¶йҖҡиҝҮеұЎж¬ЎиҜ•й”ҷдёӯзҡ„з»ҸйӘҢ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҮӘдё»е®һзҺ°зҺҜеўғеҗҢжӯҘе·ҘдҪңгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮдәӨд»ҳж•ҲиғҪдёҺиҰҶзӣ–жҲҗе°ұеҰӮдёӢпјҡ
? е№јж—¶зә§жһҒйҖҹйҖӮй…ҚпјҡеҜ№дёҖдәӣдё»жөҒжЁЎеһӢ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢ10 еҲҶй’ҹеҶ…е®һзҺ°д»ҺзҺҜеўғй…ҚзҪ®еҲ°жҺЁзҗҶ Demo иҝҗиЎҢ�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣзҹӯйӮҷеӨ§ж— ж•°жЁЎеһӢ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢ1 е№јж—¶еҶ…д№ҹеҸҜе®һзҺ°йҖӮй…ҚгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
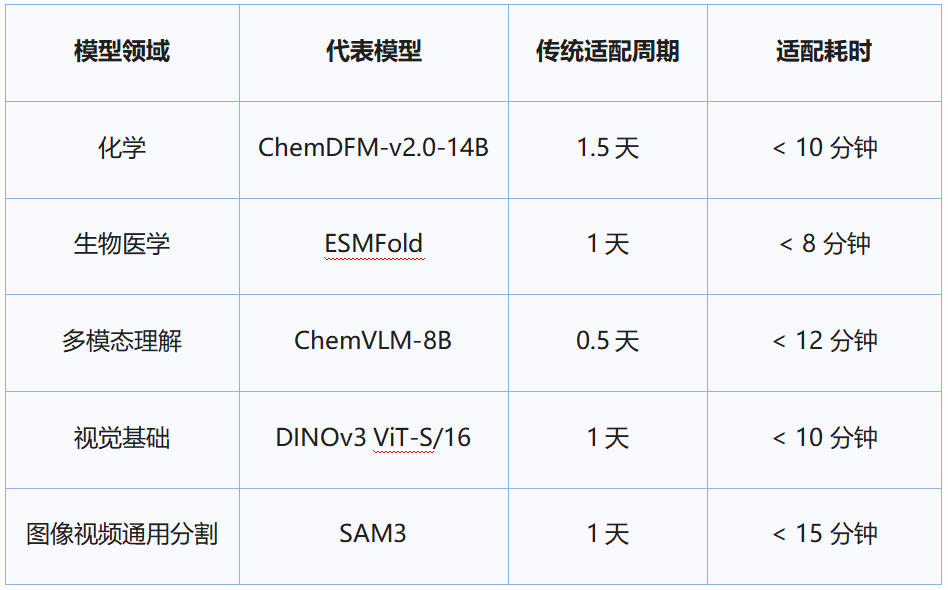
? 500+ жЁЎеһӢиҰҶзӣ–пјҡжҲ‘们йҖүеҸ–вҖңж·ұеәҰзІҫе»әвҖқдёҺвҖң规模иҮӘеҠЁеҢ–вҖқз»“еҗҲ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе®һзҺ°дәҶеҜ№ ChemDFMгҖҒESM2гҖҒDINOv3 зӯү科еӯҰжҺЁз®—дёҺеүҚжІҝи§Ҷи§үж ҮжқҶжЁЎеһӢзҡ„ж·ұеәҰйҖӮй…Қ�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣжӯӨиЎЁ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдҫқйҷ„еӨҡжҷәиғҪдҪ“еҗҲдҪңжңәйҖ �пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе®һзҺ°дәҶ 500+ жЁЎеһӢзҡ„иҮӘеҠЁйҖӮй…ҚгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮйңҖжҠҠзЁі�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҮӘеҠЁеә“дҫ§жІүдәҺ规�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣе°ҡиЎҢеҢқж©№�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢд»Јз ҒиҙЁйҮҸеҸҜиғҪеҸ—жЁЎеһӢеӨҚжқӮжқңиЈ…е“ҚеӯҳеңЁйў з°ё�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢеҗҺз»ӯе°Ҷз»“еҗҲ CI жңәйҖ иҝӣиЎҢй•ҝж•ҲиҮӘж„ҲгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
д»ҘдёӢжҳҜйғЁй—Ёдё»жөҒжЁЎеһӢзҡ„йҖӮй…ҚеҠҹеӨ«е®һжөӢпјҡ
03
жЁЎеһӢйҖӮй…ҚеҗҺзҡ„иҮӘеҠЁдјҳеҢ–жҸҗйҖҹ
еңЁдёҚеҸҳиҝҗиЎҢжЁЎеһӢеҗҺ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдёӢдёҖдёӘй—®йўҳжҳҜпјҡжЁЎеһӢжңәиғҪиӢҘдҪ•иҝӣдёҖжӯҘжҸҗеҚҮ�пјҹпјҹ�пјҹ�пјҹпјҹ�пјҹ�пјҹ�пјҹжҲ‘们ејҖеҸ‘дәҶдёҖдёӘжӣҙе…Ёйқўзҡ„жҷәиғҪдҪ“е·Ҙе…·�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢеҸҜе®һзҺ°иҮӘеҠЁдјҳеҢ–пјҡд»Ҙз«ҜеҲ°з«Ҝи§Ҷи§’иҮӘеҠЁе®ҡдҪҚжңәиғҪ瓶йўҲ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢ并йҖҡиҝҮиҮӘз•ҢиҜҙи§Јз ҒеҫӘзҺҜгҖҒжҖҘеү§йў„еӨ„зҪ®з®ЎзәҝзӯүдјҺдҝ©�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҮӘеҠЁеӨ©з”ҹ并еҲ©з”ЁдјҳеҢ–规еҲ’�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе®һзҺ°жңәиғҪжҸҗеҚҮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
жҲ‘们жҜ”еҠӣдәҶеҲқжӯҘйҖӮй…ҚиҝҮзҡ„жЁЎеһӢе’ҢиҮӘеҠЁдјҳеҢ–еҗҺзҡ„жЁЎеһӢ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢеңЁ7дёӘд»ЈиЎЁжҖ§жЁЎеһӢдёҠе®һзҺ°зі»з»ҹйӘҢиҜҒпјҡзі»з»ҹе“Қеә”еҠҹеӨ«(з”ЁP50延й•ҝжқҘиЎЎйҮҸ)еқҮеҢҖйҷҚдҪҺ18.4%�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢжңҖй«ҳйҷҚдҪҺ38.0%�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣжЁЎеһӢеҗһеҗҗеқҮеҢҖжҸҗеҚҮ 23.3%пјҲжңҖй«ҳ 64.6%пјүгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮдёӢж–ҮжҳҜе…·дҪ“зҡ„еҜ№жҜ”пјҡ
еҗҚиҜҚиҜ йҮҠпјҡ延й•ҝпјҲlatencyпјүжҢҮдёҖж¬ЎиҰҒжұӮд»ҺжҸҗи®®еҲ°иҝ”еӣһдәҶеұҖзҡ„з«ҜеҲ°з«ҜиҖ—ж—¶�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣвҖңP50 延й•ҝвҖқдёә延й•ҝж•Јеёғзҡ„ 50% еҲҶдҪҚзӮ№пјҲдёӯдҪҚж•°пјү�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢеҸҚжҳ е…ёеһӢиҰҒжұӮзҡ„е“Қеә”еҠҹеӨ«гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
жҺЁзҗҶжҸҗйҖҹжҲҗж•ҲеҜ№жҜ”
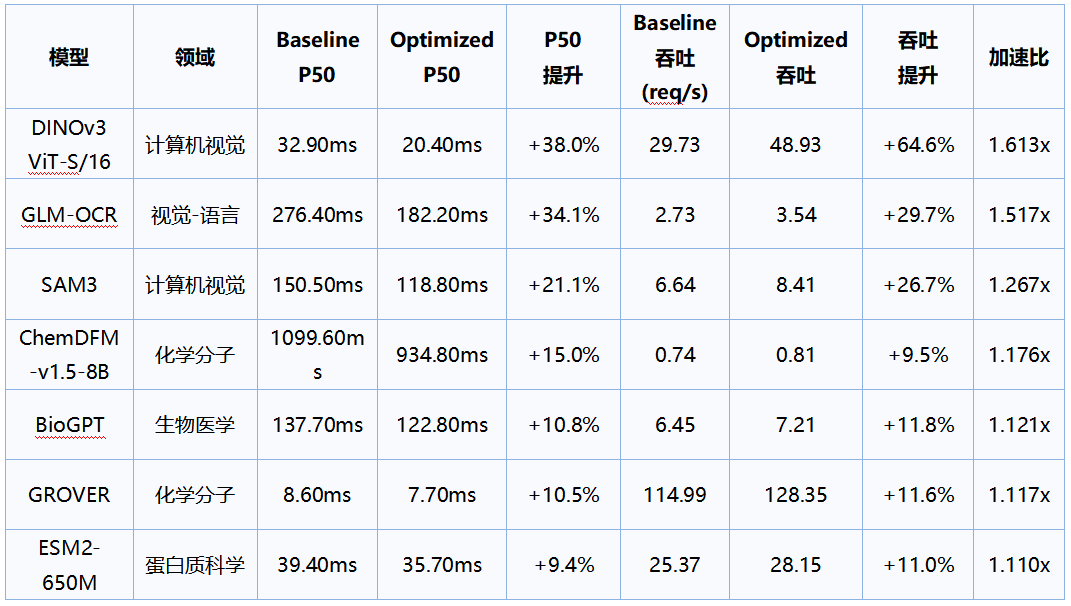
жіЁпјҡеҲқжӯҘйҖӮй…ҚеҗҺзҡ„жЁЎеһӢдёҺиҮӘеҠЁдјҳеҢ–еҗҺзҡ„зүҲжң¬еҜ№йҪҗдәҶйў„зғӯжҲҳжңҜгҖҒжөӢиҜ•ж•°жҚ®дёҺеҸӮж•°й…ҚзҪ®гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
еңЁдёҖдәӣе…ёеһӢжЎҲдҫӢдёҠ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢжҲ‘们жүҫеҲ°зҡ„иҮӘеҠЁеҠ еҝ«и§„еҲ’е’ҢжҲҗж•ҲеҰӮдёӢпјҡ
? DINOv3пјҡиҪ»йҮҸжЁЎеһӢзҡ„зңҹе®һ瓶йўҲеёёеңЁйў„еӨ„зҪ®гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮд»ҘиҮӘз•ҢиҜҙжҖҘеү§йў„еӨ„зҪ®з®Ўзәҝд»ЈжӣҝйҖҡз”Ё ImageProcessor�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдҪҝз«ҜеҲ°з«Ҝ P50 йҷҚдҪҺ 38.0%�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢеҗһеҗҗжҸҗеҚҮ 64.6%гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
? GLM-OCRпјҡйҖҡиҝҮ NPU ACL з®—еӯҗзә§дјҳеҢ–дёҺжҺЁзҗҶи№Ҡеҫ„зІҫз®ҖпјҲйў„йҳІдёҚз”ЁиҰҒзҡ„ I/Oпјү�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢP50 йҷҚдҪҺ 34.1%гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
? BioGPT / ChemDFMпјҡз”ЁиҮӘз•ҢиҜҙиҙӘеҝғи§Јз ҒеҫӘзҺҜд»ЈжӣҝйҖҡз”Ё generate()�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе…ұеҗҢ KV Cache жІ»зҗҶдёҺ ACL й«ҳжңәиғҪз®—еӯҗжҲҳжңҜ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе®һзҺ° 10%~15% зҡ„з«ҜеҲ°з«ҜеҠ еҝ«гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
? GROVERпјҡеј•е…Ҙ SDPA иһҚеҗҲжҠҠзЁіеҠӣ并жү©еӨ§йў„зғӯиҰҶзӣ–еәҸеҲ—й•ҝеәҰ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢи§ЈйҷӨе°ҫйғЁе»¶й•ҝжҜӣеҲә�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе®һзҺ° 10.5% зҡ„ P50 еҠ еҝ«гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
04
ејҖеҸ‘иҖ…иЎҢеҠЁпјҡ
еңЁжІіеҘ—�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢе…ұзӯ‘AIз”ҹжҖҒе°ҶжқҘ
зӣ®еүҚиҮӘеҠЁйҖӮй…Қе·Ҙе…·SLAI-AscendBridgeе·ІејҖжәҗ�пјӣ�пјӣпјӣпјӣ�пјӣ�пјӣпјӣиҮӘеҠЁжҸҗйҖҹдјҳеҢ–е·Ҙе…·KernelCATе·ІејҖеҗҜеҶ…жөӢ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢд»Ҙз”іиҜ·йҖ еӨ§еұҖзӣӣејҖиҜ•з”Ё�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҝҺжҺҘејҖеҸ‘иҖ…гҖҒз§‘з ”жңәжһ„дёҺдә§дёҡеҗҢдјҙе…ұеҗҢзҫҺж»ЎеӣҪдә§з®—еҠӣзҡ„жЁЎеһӢдәӨиөӢдәҲжңәиғҪе·ҘзЁӢиғҪеҠӣгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
в—Ҹ ејҖжәҗйЎ№зӣ®пјҲAscendBridgeпҪңиҮӘеҠЁйҖӮй…Қпјүпјҡhttps://gitcode.com/AI4Science/SLAI-AscendBridgeпјҲзӮ№еҮ»вҖңйҳ…иҜ»еҺҹж–ҮвҖқеҚіеҸҜи·іиҪ¬пјү
жІүж·ҖвҖңдәә + AIвҖқж·ұеәҰйҖӮй…Қз»ҸйӘҢ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҒҡз„Ұ科еӯҰжҺЁз®—дёҺеүҚжІҝж ҮжқҶжЁЎеһӢзҡ„й«ҳиҙЁйҮҸдәӨд»ҳгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
https://chongweiliu.github.io/slai-ascend-auto-adapt/dashboard/
е®һдҪҝжҜ“зӨәйҖҡиҝҮеӨҡжҷәиғҪдҪ“еҗҲдҪңе®һзҺ°зҡ„ 500+ жЁЎеһӢе…ЁиҮӘеҠЁйҖӮй…ҚжҲҗе°ұдёҺиҝҗиЎҢзҠ¶жҖҒгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
в—Ҹ жңәиғҪдјҳеҢ–иғҪеҠӣпјҲKernelCatпҪңиҮӘеҠЁжҸҗйҖҹпјүпјҡеҪ“еүҚд»ҘеҶ…жөӢAPIеӨ§еұҖзӣӣејҖ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢйқўеҗ‘еҗҲдҪңеҗҢдјҙжҸҗдҫӣжҺҘе…ҘдёҺз»“еҗҲдјҳеҢ–ж”ҜжҢҒпјҲиҝҺжҺҘз”іиҜ·еҶ…жөӢпјүгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ
зүҲжқғз”іжҳҺпјҡжң¬ж–ҮиҪ¬иҪҪиҮӘдёҪжұҹжІіеҘ—еӯҰйҷўе®ҳзҪ‘�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢд»…з”ЁдәҺиЎҢдёҡиө„и®Ҝдә’жҚўдёҺжҠҖжңҜеҲҶдә«�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдёҚд»ЈиЎЁжң¬е…¬еҸёжҖҒеәҰ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢдёҚз”ЁдәҺиҙёжҳ“з”ЁеӨ„гҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮзүҲжқғеҪ’еҺҹдҪңиҖ…еҸҠеҺҹеҮәеӨ„жүҖжңү�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢеҰӮжңүдҫөжқғ�пјҢ�пјҢ�пјҢпјҢ�пјҢ�пјҢ�пјҢ�пјҢиҜ·иҒ”зі»BBиҙқеҚҡиүҫеј—жЈ®е®һж—¶еҲ йҷӨгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮгҖӮ�гҖӮ





















_1757660066.png)


